统计量是统计理论中用来对数据进行分析、检验的变量。宏观量是大量微观量的统计平均值,具有统计平均的意义,对于单个微观粒子,宏观量是没有意义的.相对于微观量的统计平均性质的宏观量也叫统计量。需要指出的是,描写宏观世界的物理量例如速度、动能等实际上也可以说是宏观量,但宏观量并不都具有统计平均的性质,因而宏观量并不都是统计量。
定义
样本的已知函数;其作用是把样本中有关总体的信息汇集起来;是数理统计学中一个重要的基本概念。统计量依赖且只依赖于样本x1,x2,…xn;它不含总体分布的任何未知参数。
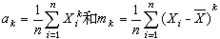
从样本推断总体(见统计推断)通常是通过统计量进行的。例如x1,x2,…,xn是从正态总体N(μ,1)(见正态分布)中抽出的简单随机样本,其中均值(见数学期望)μ是未知的,为了对μ作出推断,计算样本均值。可以证明,在一定意义下,塣包含样本中有关μ的全部信息,因而能对μ作出良好的推断。这里只依赖于样本x1,x2,…,xn,是一个统计量。
统计量样本矩
设x1,x2,…,xn是一个大小为n的样本,对自然数k,分别称 为k阶样本原

点矩和k阶样本中心矩,统称为样本矩。许多最常用的统计量,都可由样本矩构造。例如,样本均值(即α1)和样本方差 是常用的两个统计量,前者反映总体中心位置的信息,后者反映总体分散情况。还有其他常用的统计量,如样本标准差,样本变异系数S/塣,样本偏度,样本峰度等都是样本矩的函数。若(x1,Y1),(x2,Y2),…,(xn,Yn)是从二维总体(x,Y)抽出的简单样本,则样本协方差·及样本相关系数 也是常用的统计量,r可用于推断x和Y的相关性。
次序统计量
把样本X1,x2,…,xn由小到大排列,得到,称之为样本x1,x2,…
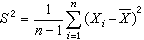
,xn的次序统计量。其中最小次序统计量x⑴最大次序统计量x(n)称为极值,在那些如年枯水量、年最大地震级数、材料的断裂强度等的统计问题中很有用。还有一些由次序统计量派生出来的有用的统计量,如:样本中位数 是总体分布中心位置的一种度量,若样本大小n为奇数,,若n为偶数,,它容易计算且有良好的稳健性。样本p分位数Zp(0
 相关推荐
相关推荐



 渝公网安备 50019002502348号
渝公网安备 50019002502348号